CMU15445 12查询优化II
前言
为什么要考虑并发问题?
-
提升性能
- 吞吐量,每秒可以处理的SQL指令
- 等待时间,单SQL指令在单线程情况下可能要6s,多线程可以缩减为3s
-
提升响应性和可用性
数据库作为底层,服务于上层系统。 提升数据库的响应性和可用性也就提高了上层系统的响应性和可用性。
-
潜在地较低的TCO(total cost of ownership)
计算硬件的费用,往往使用TCO这个指标。假设一台机器可以使用10年,10年可以处理多少条数据,处理这些数据需要多少电费。
如果提高数据库的效率,使得它处理一条数据效率更高,需要的电费更少。并行执行和并发执行如果高效,就可以节省这些费用。
数据库并行 VS 分布式
-
将数据库分布在多个机器上,以改进DBMS的不同方面
-
分布式数据库经常将数据库切分成多个节点,对于客户端来说,只需要连接上一个节点,就相当于连接了整个分布式数据库。
- 单线程的数据库和并行数据库或者分布式数据库对于同样一条SQL指令应该产生相同的结果
-
并行数据库(Parallel)
-
资源应该是相邻的 假设数据库是多线程并发的。相邻指的是线程都在同一个CPU上,同一个内存上
-
资源之间的通信是高速执行的。 对于在同一个内存中的通信,可以直接使用内存通信,所以通信是高速的
-
并行数据库的进程或线程的通信是简单可靠的。 多线程并发的线程通信是通过内存进行的,这是简单可靠的。
-
-
分布式数据库(Distributed)
-
资源之间是很远的。 因为资源再不同的节点上,不同节点的物理位置可能相差很远,跨市跨省跨国跨洲之类。
-
资源之间的通信是很慢的。 对于不在同一个节点上的通信,需要使用网络通信,而网络通信相较于同一台机器上的内存通信是很慢的。
-
分布式数据库的花费和产生的问题不可被忽略。 通信之间产生的问题以及通信速度较慢以及花费等问题必须被考虑。
-
主要内容
处理模型(Process Model)
-
一个数据库的处理模型(Process Model)定义的是:如何构建一个支持多用户的并发请求系统。
-
一个 worker 是数据库的一个组件,在收到来自用户的请求后,系统将请求拆分成多个部分,每个部分交由一个 worker 执行。
-
三大方向
- 每个 worker 是一个进程 (Process per DBMS Worker)
- 进程池 (Process Pool)
- 每个 worker 是一个线程 (Thread per DBMS Worker)
Process per DBMS Worker
每一个 worker 分配一个进程去执行相应的任务。在 Linux 下,这个进程会对应到一个具体的 pid 。
- 依赖于操作系统的进程调度
- 操作系统开辟一个共享内存来方便进程间通信,共享全局的数据结构
- 一个进程崩溃不会使得整个系统宕机
- 例子:IBM、DB2、Postgres、Oracle
问题:进程开销过大,如果每个 worker 一个进程,开辟进程与回收进程都会产生很多开销,进而考虑优化,就是池化。
Process Pool
每一个 worker 从进程池中请求一个空闲进程。
- 仍然依赖于操作系统的进程调度和共享内存
- 对于 CPU 的缓存局部性是不利的(
这块没讲清楚) - 例子:IBM、DB2、Postgres
Thread per Worker
一个进程,但是拥有多个 workder 线程
- DBMS 负责其 workder 的调度
- 使用或者不使用 dispatcher(分发器,将一个SQL指令拆分成多个子任务)
- 线程崩溃可能会使得进程崩溃
- 例子:IBM、DB2、MSSQL、MySQL、Oracle
三种处理模型
- Thread per Worker 的优点在于:
- 每个上下文切换(context switch)的开销更少
- 不需要管理共享内存(同一进程下的多个线程天然是共享内存的,只有进程拥有CPU分配的资源)
- Thread per Worker 模型并不意味着数据库支持单SQL语句中各部分是并发的,这只是针对多个SQL语句,每个SQL语句是并发的。
针对单个SQL语句进行并发有另外的讨论
调度
针对每个查询计划,DBMS需要去确定何时、在哪里以及如何执行。
- 把单个查询计划切分成多少个子任务
- 每个任务需要多少个CPU资源
- 哪些CPU需要执行哪些任务
- 如何将执行完毕得到返回子任务的结果再拼接起来
DBMS 应该控制如何调度,而不是完全交由操作系统去调度
Inter/Intra-Query Parallelism
查询之间的并发处理和查询内部的并发处理
-
Inter-Query: 不同查询的并发执行
- 提升吞吐量(throughput) & 降低等待时间(latency)
-
Intra-Query: 并发地执行单个查询的所有子任务
- 降低需要很长时间运行的查询(long-running queries)的等待时间(latency)
Inter-Query Paralleism
-
通过允许多个查询的同时执行来提高整体性能
-
如果所有的并发查询都是只读的,只读查询间的冲突是很少的,所以只需要很少的维护和操作就可以了。
-
如果多个查询在同时更新数据库,并发执行这些查询很难保证查询的顺序,也就是说需要并发控制去维护数据库的数据正确性。(lecture15,并发控制)
Intra-Query Paralleism
-
通过并行执行单个查询,提升单个查询的性能
-
从 producer/consumer 的角度来考虑如何进行每个操作(比如投影,聚集,连接这些算子)执行的组织问题。
-
每个操作都有并发的版本,有如下两种并发思路
- 多线程访问集中式数据结构(centralized data structures):在这种策略中,所有线程共享一个数据结构,因此需要确保在进行读写操作时遵循一定的同步规则,以防止数据不一致和竞态条件。
- 使用分区(partitioning)划分工作:这种策略将数据结构分成多个独立的部分(分区),每个线程只能访问其所分配的分区。这样可以减少锁定和同步的开销,同时提高并行性。
并发版本的 Grace Hash Join (Paralleism Grace Hash Join)
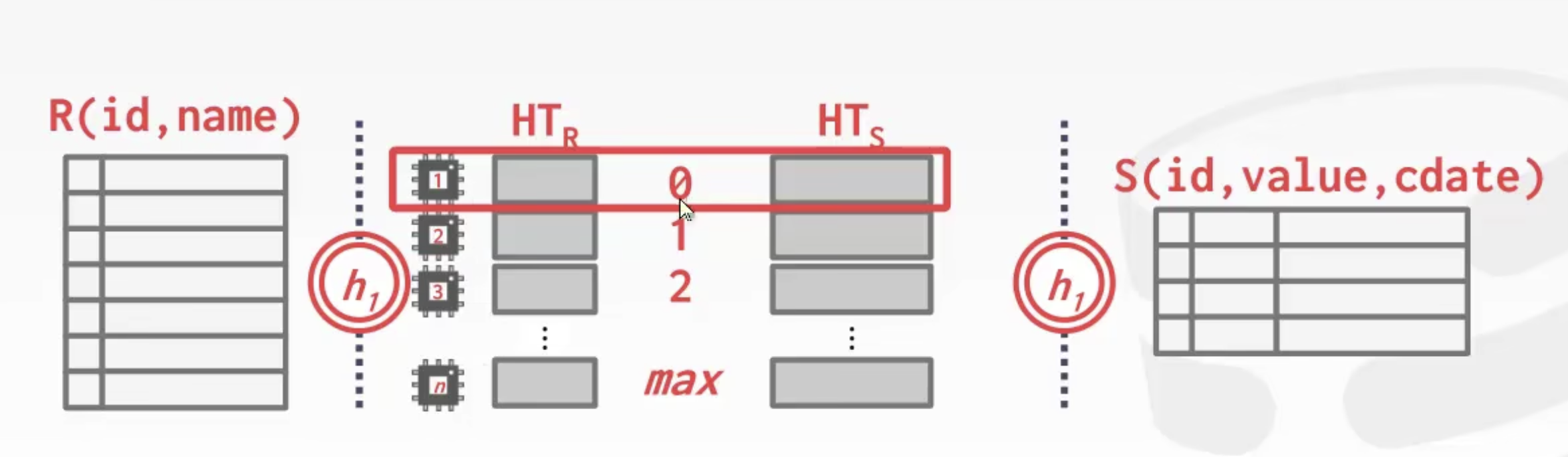
如图所示R 表和 S 表都做一个 Hash Join,然后写入硬盘后得到一堆桶。这里可以看到对于 R 表和 S 表,各有 max + 1 个桶,那么对于 R 表的第一个桶和 S 表的第一个桶,使用一个 worker 去进行 join。一共使用 max + 1 个 worker 即可并行地进行 join。
Intra-Query Paralleism 的三种方式
-
Intra-Operator(Horizontal,水平的),将 query plan tree 水平切分
-
Intra-Operator(Vertical,垂直的),将 query plan tree 垂直切分
-
Bushy(Horizontal 和 Vertical 结合)
Intra-Operator(Horizontal)
将数据可以被分成 n 块,让 n 个线程分别处理这 n 块数据。
DBMS 在 query plan 中插入一个 exchange 算子来
- 合并来自多个子算子的结果(聚集)
- 将父算子的数据拆分给每个子算子进行计算(拆分)
即用来进行数据的聚集、拆分。
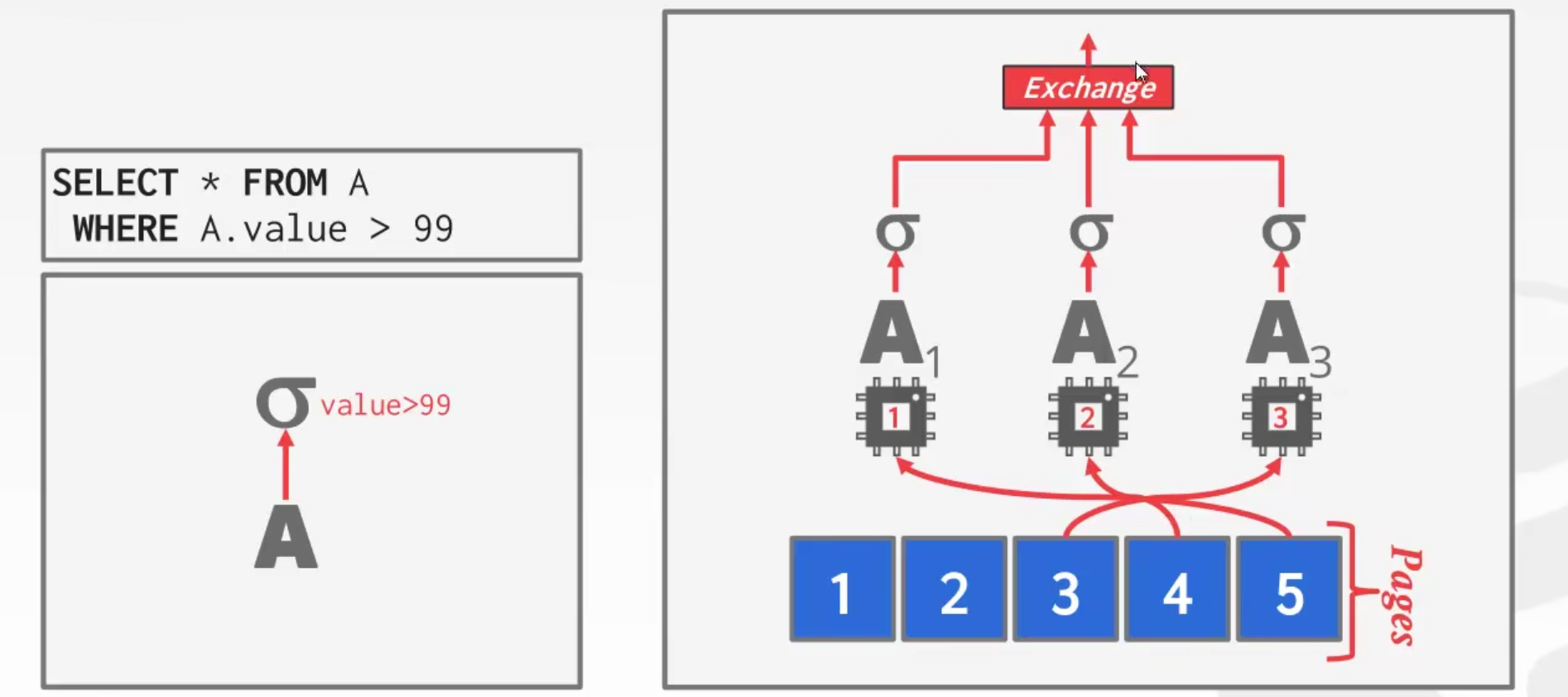
对于这个图中的例子,exchange 先将数据拆分成 5 pages,并将 1 个选择算子 $\sigma$ 拆分成 3 个选择算子 $\sigma$ 。
使用 3 个 worker 分别执行 $\sigma_1, \sigma_2, \sigma_3$,开始时,$\sigma_1, \sigma_2, \sigma_3$ 分别执行 page1,page2,page3 由于是并行的,所以可以粗略认为这三个算子的执行速度是一样的,执行结束后,$\sigma_1, \sigma_2$ 再分别执行 page4 和 page5。
这里需要注意的是,如果 exchange 的父算子是一个 projection 投影算子 $\prod$ ,其调用子算子 $\sigma$ 的 $next()$ 时,子算子应该将所有符合条件的数据都拿到,否则这里的并发对于子算子 $\sigma$ 来说就是假的并发。
Exchange Operator(Exchange 算子)
Exchange 算子分为如下三种
-
Gather算子是指聚集。
将数据拆分成多份,多个 worker 并发执行,获得每个 worker 的执行结果,由 Gather 算子对结果进行聚集。
-
Distribute算子是指分配。
将数据拆分成多份,由多个 worker 并发执行。
-
Repartition算子是指先聚集再分配
将n个算子的结果先进行聚集成一份,然后再拆分成m份输出(这种情况是父算子为 2 个 worker,而子算子为 3 个worker的情况)。
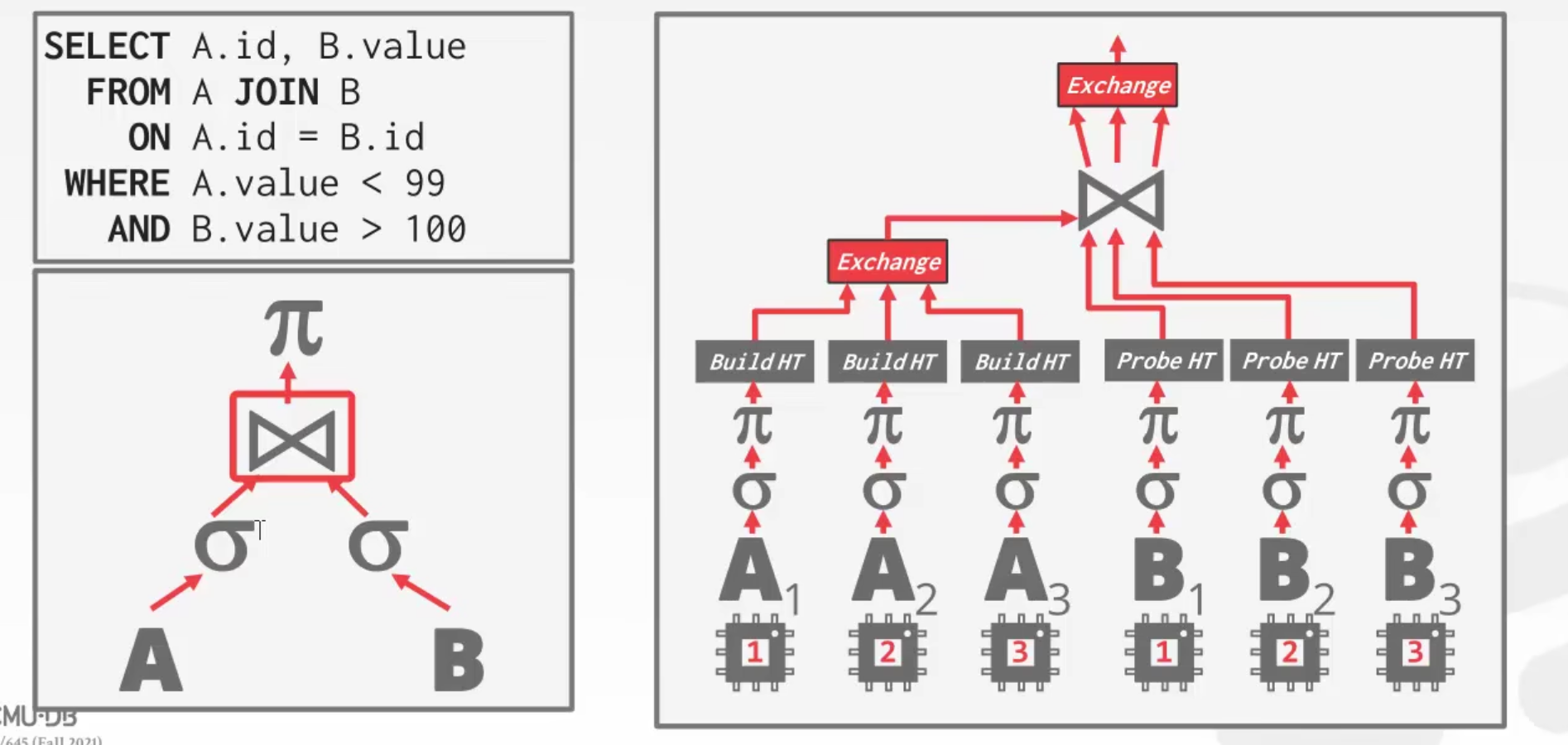 这个例子是在说明 Intra-Query。这里在实际执行时,先进行投影,然后再连接,去掉不必要的列。
这个例子是在说明 Intra-Query。这里在实际执行时,先进行投影,然后再连接,去掉不必要的列。
对于 A 表,将其数据拆分为 3 部分,使用 3 个 worker 并行执行,然后由 exchange 算子聚集得到一个整的 hash 表。
对于 B 表,也将其数据拆分为 3 部分,使用 3 个 worker 并行执行,但是对于 B 表来说,其数据的拆分并不能保证所有 join 列相同的行都被拆分到同一个 worker 下,
所以需要对每个 B 的 worker 得到的结果都去与 A 进行 join。B 的 3 个 worker 与 A join 得到的结果交由一个 exchange 算子进行聚集。
Intra-Operator(Vertical)
对于每一个层级的算子,都会有一堆 worker 处理这个层级的操作。
然后将结果交由上一个层级的算子进行,但是如果子层级的 worker 很慢,那么父层级的算子就也被迫很慢。
也称为 pipline parallelism
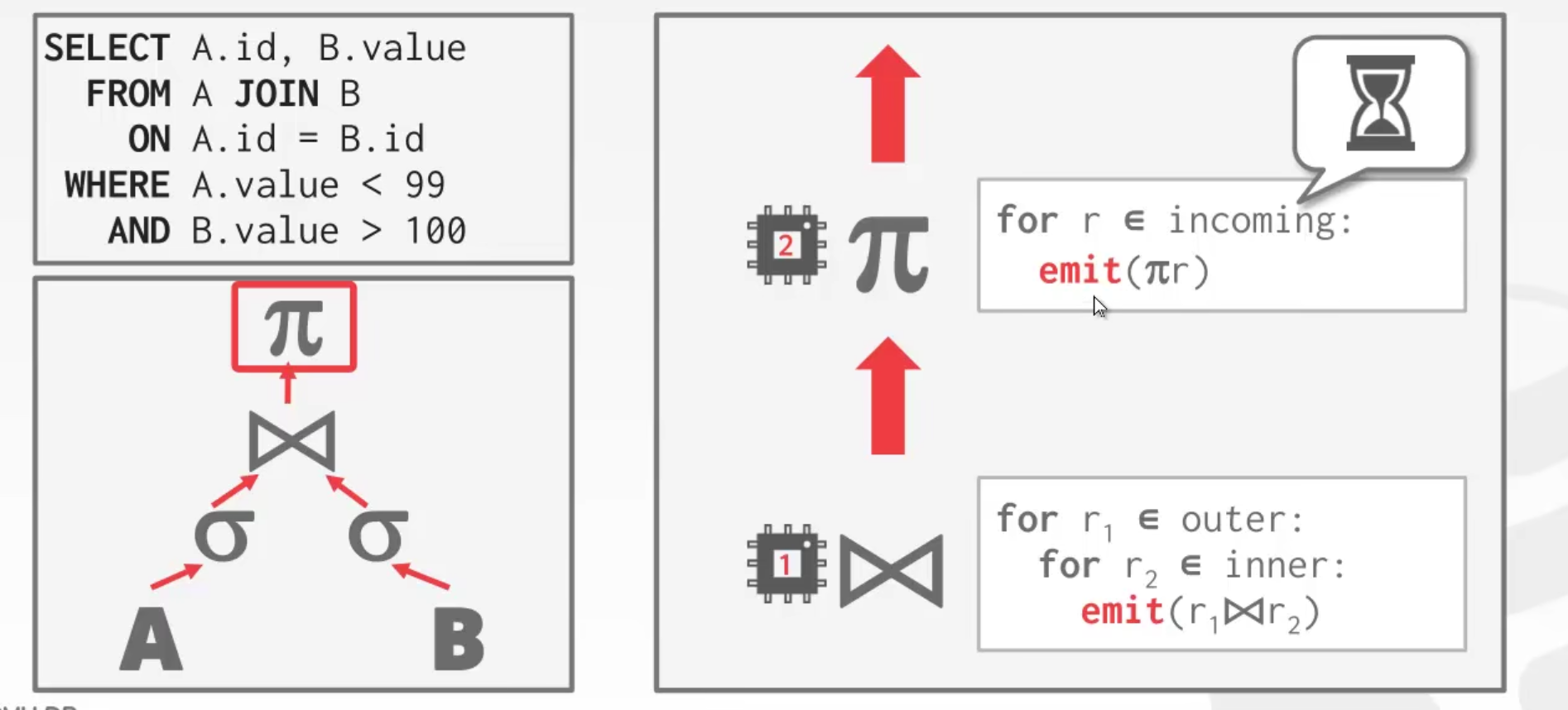
观察发现
在面向磁盘的数据库中,大多的瓶颈在于读写磁盘,之前讨论的并行执行大多都是考虑数据已经被加载进内存的情况。
使用多进程或者多线程方式去并行执行 query 并不会提升效率,还有可能降低效率。这是因为磁盘是主要的瓶颈。
- 事实上,如果每个 worker 都去访问磁盘的不同部分(即对于一份数据分成若干份,每个 worker 读取对应的一份,一个磁盘疲于应付多个 worker ,反而降低了效率)会使得情况更坏。
I/O Pararllelism (I/O并发)
将 DBMS 拆分到多个存储设备上(将数据物理上拆分)
- 每个数据有多个磁盘
- 每个磁盘一个数据库
- 每个磁盘一种关系
- 将一种关系拆分到多个磁盘上
- …
Multi-Disk Parallelism (多磁盘并发)
在操作系统或者硬件层面来存储DBMS的文件到多个存储设备上
- storage appliances
- RAID(redundant array of independent disks,独立磁盘冗余阵列) configuration
对于操作系统是透明的。
- RAID0(Striping,一个文件拆分成多份,每份存到一个磁盘上,一个磁盘损坏则对应的文件都损坏)
- RAID1(Mirroring,一份数据存到多个磁盘上)
- RAID5(三个盘,两个磁盘存数据,一个盘存另外两个盘的异或,如果数据盘1损坏,可以通过异或盘与数据盘1进行异或获得数据盘2的数据)
- 基于 RAID5,可以存多个异或,这样当多个盘损坏也能通过异或操作恢复数据。
分库(数据库拆分)
-
一些DBMS允许指定每个库存放的磁盘位置
- 缓存池管理器将一个页映射到一个磁盘位置(意思是存储一个库对应的磁盘位置)
-
如果DBMS将每个库存储在分开的目录(即一个库一个目录)中,操作文件系统级别是很容易的
- 如果事务是更新多个数据库,那么DBMS恢复日志文件仍然需要是共享的
分区(将单个表物理上分为多个表)
-
垂直分区
-
假设一个表有列(A,B,C,D),其中D列中每行的数据量很大,但是D列在实际使用中很少用,则可以将其在物理上拆分为(A,B,C)和(D) 两个表。这样在查询该表时,就可以进行并发了,因为 (A,B,C) 的数据量与 (D) 基本一致,这样使用 多个 worker 进行并发查询,就可以加速。
通常是将一种表分为:高频但是数据量小的、低频但是数据量大的 两种类型的表。
-
-
水平分区
- 假设一张表有 100 万行数据,将这张表水平分成两张 50 万行数据的表。这两张表分到不同的磁盘中去,由数据库去负责在查询时将这两张表统一起来(数据库要知道这两张表在逻辑上是一张表)。分表时,需要告诉数据库分表的标准(以哪一列来分,比如 id <= 500000 的在一张表,id > 500000 的在一张表)。
还有一些分库分表的中间件,它们是一些网关(Gateway),连上这些网关的方式类似于连接上数据库,但是这些中间件不负责存储数据,只负责分割数据(比如将数据分成 5 部分,连着 5 个数据库,每个数据库在不同节点上),将数据分配到不同的数据库上。
最初始的分布式数据库思想:就是将数据拆分成 n 份,创建多个数据库去存储每份数据。当进行查询、删除和更新时,也会将对应的操作通过网关分别对应到 n 个数据库上去进行操作。
总结
并发执行是非常重要的,几乎所有的主流数据库都实现了(至少是逻辑上的SQL语句的并发,主流数据库都实现了。)。
上述问题说起来很简单,但实际实现时的问题很多:
- Coordination Overhead(不同 worker 之间的开销协调,比如一个 worker 需要负责大量的数据,而另一个 worker 只需要负责少部分数据,其实总开销取决于开销更大的 worker ,如果平均两个 worker 的开销,就可以降低总开销
- Scheduling(不同 worker 之间的调度
- Concurrency Issues(不同线程之间的并发,比如什么时候需要加锁
- Resource Contention(资源冲突,比如两个 worker 都要读写磁盘